This paper is mainly about converting the original format of a markdown file written in Chinese to a markdown file written in English (or translation between two other languages) to solve the language gap.
1. Register as Baidu Translation Developer
There are many translation websites, like Google Translation, Baidu Translation,DeepL.DeepL as a rising star performs very well, the author uses DeepL to translate word documents can solve the problem of scrambling very well.The author strongly recommends using DeepL to translate documents instead of Google to translate them.But for the author who wants to translate Chinese into English, Baidu, as the largest search engine in Chinese, obviously has the largest Chinese corpus and performs better in the task of translating Chinese into English.

Click to enterBaidu TranslateRegistered as a developer, Baidu's vertical translation is obviously the best choice because the author is engaged in the science and technology industry.
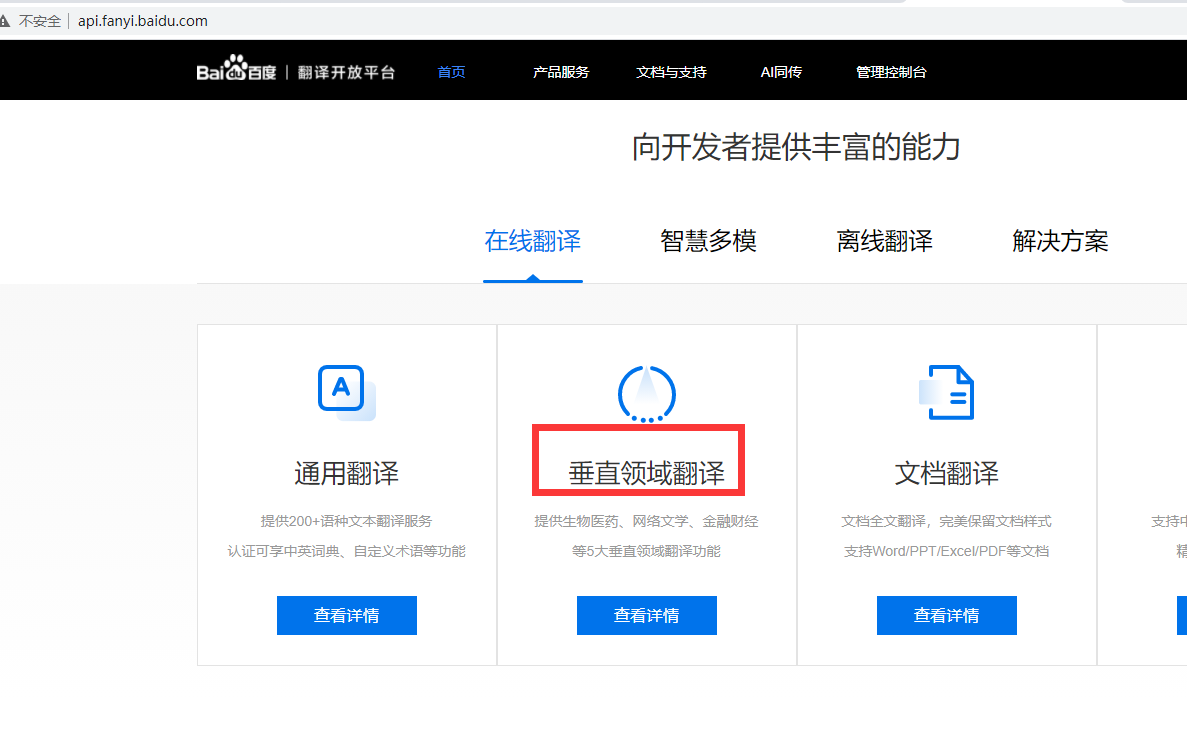

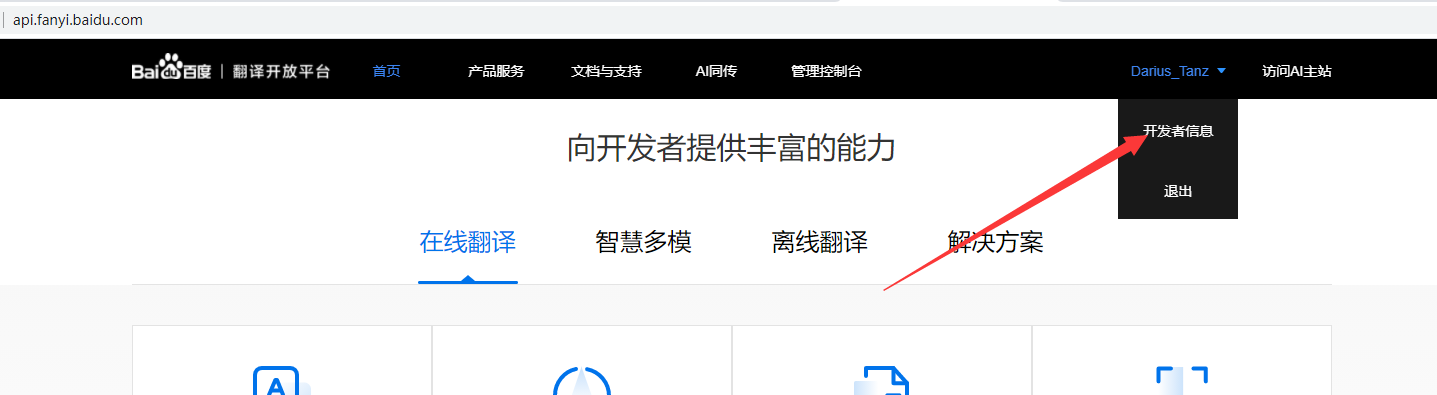
After successful registration, click on the upper right corner to select the developer information.
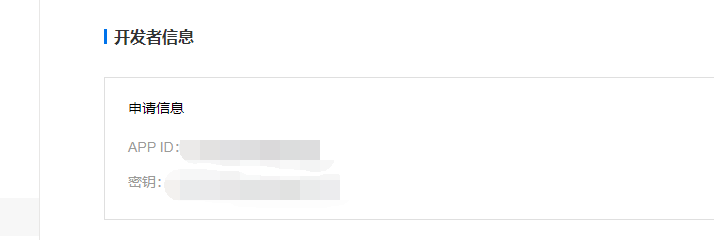
We'll see our ID and key, which we'll use later
2. Translate Chinese into English using Baidu Translation API
In addition to translating Chinese into English, we can also translate other languages with reference to their officialFile.
functiontranslet2english(q),qIs a Chinese string to be translated, no more than 2000 characters, no line breaks, usingutf-8Encoding, function returns reacted English string
#百度垂直领域翻译API,不包含词典、tts语音合成等资源,如有相关需求请联系translate_api@baidu.com
# 2020.07.28 更新,原url拼接错误,感谢热心网友指正
# coding=utf-8
#http://api.fanyi.baidu.com/doc/22
import http.client
import hashlib
import urllib
import random
import json
import re
def translet2english(q):
# 你的APP ID,请修改成您的
appid = '2021010700066xxxx'
# 你的密钥,请修改成您的
secretKey = 'My7cCx368vqBmauExxxx'
# 百度翻译 API 的 HTTP 接口
myurl = 'http://api.fanyi.baidu.com/api/trans/vip/fieldtranslate'
httpClient = None
fromLang = 'auto' #原文语种
toLang = 'en' #译文语种
salt = random.randint(32768, 65536)
domain = 'electronics'
sign = appid + q + str(salt) + domain + secretKey
sign = hashlib.md5(sign.encode()).hexdigest()
myurl = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(q) + '&from=' + fromLang + '&to=' + toLang + '&salt=' + str(salt) + '&domain=' + domain + '&sign=' + sign
try:
httpClient = http.client.HTTPConnection('api.fanyi.baidu.com')
httpClient.request('GET', myurl)
# response是HTTPResponse对象
response = httpClient.getresponse()
result_all = response.read().decode("utf-8")
result = json.loads(result_all)
#print (result)
return result['trans_result'][0]['dst']
except Exception as e:
print ('error')
finally:
if httpClient:
httpClient.close()
3. Convert Chinese markdown toutf-8Code
changeFileType(filename_in,filename_out='C:\\Users\\19532\\Desktop\\testout.md'): willfilename_inConvert toutf-8Codedfilename_out, backfilename_out
filename_in: Files to be converted
filename_out: converted file
# _*_ coding: utf-8 _*_
import pandas as pd
import chardet
import codecs
def checkFileType(filename):
try:
with open(filename, 'rb') as f:
data = f.read()
encoding_type = chardet.detect(data)
return encoding_type['encoding']
except Exception as e:
return 'utf-8'
def changeFileType(filename_in,filename_out='C:\\Users\\19532\\Desktop\\testout.md'):
# 输入文件的编码类型
encode_in = checkFileType(filename_in)
# 输出文件的编码类型
encode_out = 'utf-8'
with codecs.open(filename=filename_in, mode='rb', encoding=encode_in, errors='ignore') as fi:
data = fi.read()
with open(filename_out, mode='w', encoding=encode_out) as fo:
fo.write(data)
fo.close()
return filename_out
4. Parse markdown file to translate Chinese into English
findPos(contends): FindcontendsUntranslatable markdown tags in strings and untranslatable code, formulas, and so on.
Markdown tags are referenced fromRookie Bird Tutorial
# 获取文件的内容
def get_contends(path):
with open(path,'r',encoding='utf-8', errors='ignore') as file_object:
contends = file_object.read()
return contends
# 找到markdown标记符
def findPos(contends):
pattern = re.compile(r'(-+--|#+ |\$[^\$]+\$|\$\$[^\$]+\$\$|\[|\]|\([^\)]+\)|_+|\*+ |\++ |>+ |`[^`]+`|```[^`]+```|\|+|\n+|---[^-]+---|<[^>]*>)',re.DOTALL)
pos=[]
def double(matched):
pos.append(matched.span())
re.sub(pattern, double,contends)
return pos
trans2english(contends,pos): except in the stringfindPos(contends)A string found outside the location of an untranslatable string is translated into English
def trans2english(contends,pos):
l=0
r=0
i=0
eng=''
while r<len(contends) and i<len(pos):
a=pos[i][0]
b=pos[i][1]
if l<a:
r=a
if contends[l:r]!=' ':
eng+=translet2english(contends[l:r])
else:
eng+=contends[l:r]
l=r
else:
l=b
r=b
eng+=contends[a:b]
i=i+1
if r<len(contends):
if contends[r:len(contends)]!=' ':
eng+=translet2english(contends[r:len(contends)])
else:
eng+=contends[r:len(contends)]
return eng
readAndTranslate(fileIn,filename_out): willfileInTranslate tofilename_out
def readAndTranslate(fileIn='C:\\Users\\19532\\Desktop\\Myblog\\posts\\about.md',filename_out='C:\\Users\\19532\\Desktop\\testenglish.md'):
filename=changeFileType(fileIn)
contends=get_contends(filename)
pos=findPos(contends)
ans=trans2english(contends,pos)
with open(filename_out, mode='w', encoding= 'utf-8') as fo:
fo.write(ans)
fo.close()
return ans
5. All Codes
import pandas as pd
import chardet
import codecs
import http.client
import hashlib
import urllib
import random
import json
import re
def translet2english(q):
# 你的APP ID
appid = '2021010700066xx'
# 你的密钥
secretKey = 'My7cCx368vqBmauE1Bxxxx'
# 百度翻译 API 的 HTTP 接口
myurl = 'http://api.fanyi.baidu.com/api/trans/vip/fieldtranslate'
httpClient = None
fromLang = 'auto' #原文语种
toLang = 'en' #译文语种
salt = random.randint(32768, 65536)
domain = 'electronics'
sign = appid + q + str(salt) + domain + secretKey
sign = hashlib.md5(sign.encode()).hexdigest()
myurl = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(q) + '&from=' + fromLang + '&to=' + toLang + '&salt=' + str(salt) + '&domain=' + domain + '&sign=' + sign
try:
httpClient = http.client.HTTPConnection('api.fanyi.baidu.com')
httpClient.request('GET', myurl)
# response是HTTPResponse对象
response = httpClient.getresponse()
result_all = response.read().decode("utf-8")
result = json.loads(result_all)
#print (result)
return result['trans_result'][0]['dst']
except Exception as e:
print ('error')
finally:
if httpClient:
httpClient.close()
def checkFileType(filename):
try:
with open(filename, 'rb') as f:
data = f.read()
encoding_type = chardet.detect(data)
return encoding_type['encoding']
except Exception as e:
return 'utf-8'
def changeFileType(filename_in,filename_out='C:\\Users\\19532\\Desktop\\testout.md'):
# 输入文件的编码类型
encode_in = checkFileType(filename_in)
# 输出文件的编码类型
encode_out = 'utf-8'
with codecs.open(filename=filename_in, mode='rb', encoding=encode_in, errors='ignore') as fi:
data = fi.read()
with open(filename_out, mode='w', encoding=encode_out) as fo:
fo.write(data)
fo.close()
return filename_out
# 获取文件的内容
def get_contends(path):
with open(path,'r',encoding='utf-8', errors='ignore') as file_object:
contends = file_object.read()
return contends
def findPos(contends):
pattern = re.compile(r'(-+--|#+ |\$[^\$]+\$|\$\$[^\$]+\$\$|\[|\]|\([^\)]+\)|_+|\*+ |\++ |>+ |`[^`]+`|```[^`]+```|\|+|\n+|---[^-]+---|<[^>]*>)',re.DOTALL)
pos=[]
def double(matched):
pos.append(matched.span())
re.sub(pattern, double,contends)
return pos
def trans2english(contends,pos):
l=0
r=0
i=0
eng=''
while r<len(contends) and i<len(pos):
a=pos[i][0]
b=pos[i][1]
if l<a:
r=a
if contends[l:r]!=' ':
eng+=translet2english(contends[l:r])
else:
eng+=contends[l:r]
l=r
else:
l=b
r=b
eng+=contends[a:b]
i=i+1
if r<len(contends):
if contends[r:len(contends)]!=' ':
eng+=translet2english(contends[r:len(contends)])
else:
eng+=contends[r:len(contends)]
return eng
def readAndTranslate(fileIn='C:\\Users\\19532\\Desktop\\Myblog\\typora\\如何优雅的将中文markdown文件转换为英文markdown文件.md',filename_out='C:\\Users\\19532\\Desktop\\Myblog\\typora\\如何优雅的将中文markdown文件转换为英文markdown文件eng.md'):
filename=changeFileType(fileIn)
contends=get_contends(filename)
pos=findPos(contends)
ans=trans2english(contends,pos)
with open(filename_out, mode='w', encoding= 'utf-8') as fo:
fo.write(ans)
fo.close()
if __name__ == '__main__':
fileIn='C:\\Users\\19532\\Desktop\\Myblog\\typora\\如何优雅的将中文markdown文件转换为英文markdown文件.md'
filename_out=fileIn[:-3]+'eng.md'
readAndTranslate(fileIn,filename_out)

