本文主要是讲述将一个用中文写的markdown文件原格式转换为英文写的markdown文件(或者其他两种语言的互译),以解决语言鸿沟。
1. 注册成为百度翻译开发者
翻译网站有很多,相谷歌翻译、百度翻译、DeepL。DeepL作为后起之秀表现很出色,笔者用DeepL翻译word文档能够很好的解决乱码问题。笔者强烈推荐使用DeepL翻译文档而不是谷歌翻译。但是对于笔者想要中文翻译成英文来说,百度作为中文最大的搜索引擎,显然拥有最大的中文语料库,在中文翻译成英语任务表现上更为优秀。

点击进入百度翻译注册成为开发者,由于笔者从事科技行业,百度的垂直领域翻译显然是最好的选择.
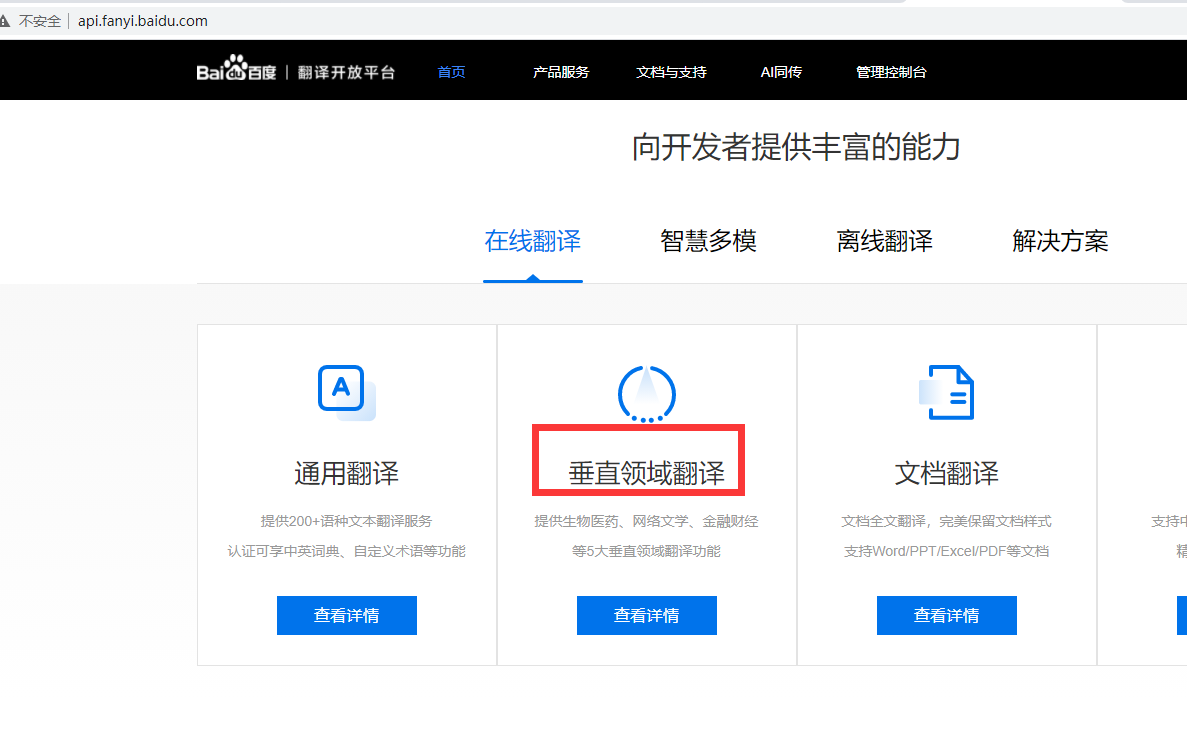

注册成功后,点击右上角,选择开发者信息。
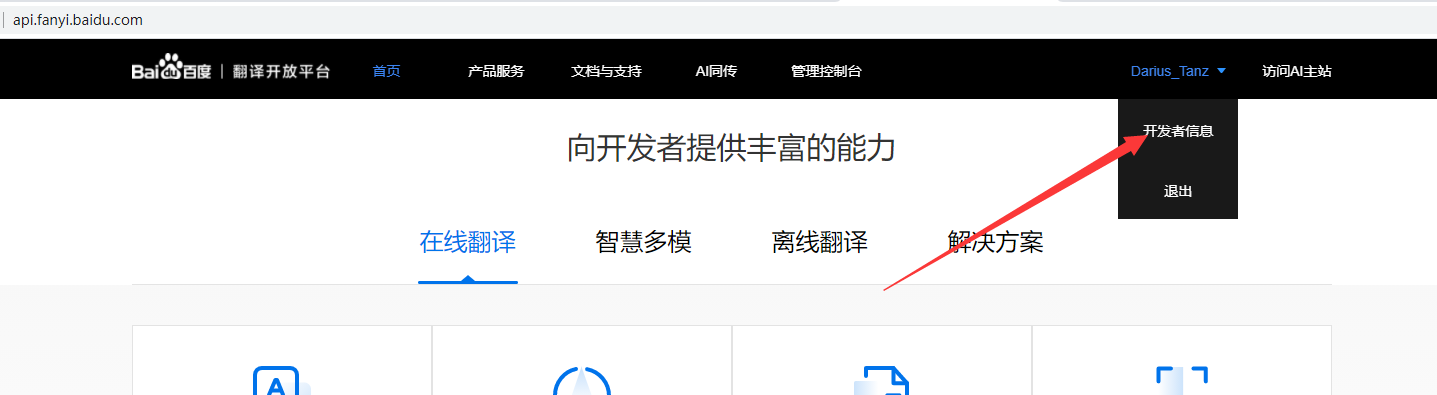
我们会看到自己的id和密钥,后面会用到
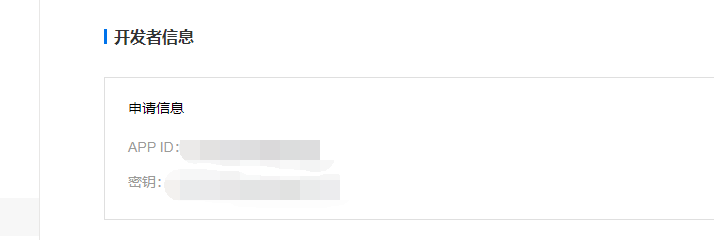
2. 利用百度翻译API将中文翻译成英文
我们除了可以将中文翻译成中文翻译成英文,我们也可以实现其他语言的互译,具体可以参照其官方的文档。
函数translet2english(q),q是待翻译中文字符串,不超过2000个字符,不含有换行符,使用utf-8编码,函数返回反应后的英文字符串
#百度垂直领域翻译API,不包含词典、tts语音合成等资源,如有相关需求请联系translate_api@baidu.com
# 2020.07.28 更新,原url拼接错误,感谢热心网友指正
# coding=utf-8
#http://api.fanyi.baidu.com/doc/22
import http.client
import hashlib
import urllib
import random
import json
import re
def translet2english(q):
# 你的APP ID,请修改成您的
appid = '2021010700066xxxx'
# 你的密钥,请修改成您的
secretKey = 'My7cCx368vqBmauExxxx'
# 百度翻译 API 的 HTTP 接口
myurl = 'http://api.fanyi.baidu.com/api/trans/vip/fieldtranslate'
httpClient = None
fromLang = 'auto' #原文语种
toLang = 'en' #译文语种
salt = random.randint(32768, 65536)
domain = 'electronics'
sign = appid + q + str(salt) + domain + secretKey
sign = hashlib.md5(sign.encode()).hexdigest()
myurl = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(q) + '&from=' + fromLang + '&to=' + toLang + '&salt=' + str(salt) + '&domain=' + domain + '&sign=' + sign
try:
httpClient = http.client.HTTPConnection('api.fanyi.baidu.com')
httpClient.request('GET', myurl)
# response是HTTPResponse对象
response = httpClient.getresponse()
result_all = response.read().decode("utf-8")
result = json.loads(result_all)
#print (result)
return result['trans_result'][0]['dst']
except Exception as e:
print ('error')
finally:
if httpClient:
httpClient.close()
3. 将待翻译中文markdown转换为utf-8编码
changeFileType(filename_in,filename_out='C:\\Users\\19532\\Desktop\\testout.md'):将filename_in转换为utf-8编码的filename_out,返回filename_out
filename_in:待转换的文件
filename_out:转换后的文件
# _*_ coding: utf-8 _*_
import pandas as pd
import chardet
import codecs
def checkFileType(filename):
try:
with open(filename, 'rb') as f:
data = f.read()
encoding_type = chardet.detect(data)
return encoding_type['encoding']
except Exception as e:
return 'utf-8'
def changeFileType(filename_in,filename_out='C:\\Users\\19532\\Desktop\\testout.md'):
# 输入文件的编码类型
encode_in = checkFileType(filename_in)
# 输出文件的编码类型
encode_out = 'utf-8'
with codecs.open(filename=filename_in, mode='rb', encoding=encode_in, errors='ignore') as fi:
data = fi.read()
with open(filename_out, mode='w', encoding=encode_out) as fo:
fo.write(data)
fo.close()
return filename_out
4. 解析markdown文件将中文翻译成英文
findPos(contends):找到contends字符串中的不能翻译的markdown标记符和不能翻译的代码、公式等等。
markdown标记符参考自菜鸟教程
# 获取文件的内容
def get_contends(path):
with open(path,'r',encoding='utf-8', errors='ignore') as file_object:
contends = file_object.read()
return contends
# 找到markdown标记符
def findPos(contends):
pattern = re.compile(r'(-+--|#+ |\$[^\$]+\$|\$\$[^\$]+\$\$|\[|\]|\([^\)]+\)|_+|\*+ |\++ |>+ |`[^`]+`|```[^`]+```|\|+|\n+|---[^-]+---|<[^>]*>)',re.DOTALL)
pos=[]
def double(matched):
pos.append(matched.span())
re.sub(pattern, double,contends)
return pos
trans2english(contends,pos):将字符串中除了findPos(contends)找到的不能翻译的字符串所在位置之外的位置的字符串翻译成英文
def trans2english(contends,pos):
l=0
r=0
i=0
eng=''
while r<len(contends) and i<len(pos):
a=pos[i][0]
b=pos[i][1]
if l<a:
r=a
if contends[l:r]!=' ':
eng+=translet2english(contends[l:r])
else:
eng+=contends[l:r]
l=r
else:
l=b
r=b
eng+=contends[a:b]
i=i+1
if r<len(contends):
if contends[r:len(contends)]!=' ':
eng+=translet2english(contends[r:len(contends)])
else:
eng+=contends[r:len(contends)]
return eng
readAndTranslate(fileIn,filename_out):将fileIn翻译为filename_out
def readAndTranslate(fileIn='C:\\Users\\19532\\Desktop\\Myblog\\posts\\about.md',filename_out='C:\\Users\\19532\\Desktop\\testenglish.md'):
filename=changeFileType(fileIn)
contends=get_contends(filename)
pos=findPos(contends)
ans=trans2english(contends,pos)
with open(filename_out, mode='w', encoding= 'utf-8') as fo:
fo.write(ans)
fo.close()
return ans
5. 全部代码
import pandas as pd
import chardet
import codecs
import http.client
import hashlib
import urllib
import random
import json
import re
def translet2english(q):
# 你的APP ID
appid = '2021010700066xx'
# 你的密钥
secretKey = 'My7cCx368vqBmauE1Bxxxx'
# 百度翻译 API 的 HTTP 接口
myurl = 'http://api.fanyi.baidu.com/api/trans/vip/fieldtranslate'
httpClient = None
fromLang = 'auto' #原文语种
toLang = 'en' #译文语种
salt = random.randint(32768, 65536)
domain = 'electronics'
sign = appid + q + str(salt) + domain + secretKey
sign = hashlib.md5(sign.encode()).hexdigest()
myurl = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(q) + '&from=' + fromLang + '&to=' + toLang + '&salt=' + str(salt) + '&domain=' + domain + '&sign=' + sign
try:
httpClient = http.client.HTTPConnection('api.fanyi.baidu.com')
httpClient.request('GET', myurl)
# response是HTTPResponse对象
response = httpClient.getresponse()
result_all = response.read().decode("utf-8")
result = json.loads(result_all)
#print (result)
return result['trans_result'][0]['dst']
except Exception as e:
print ('error')
finally:
if httpClient:
httpClient.close()
def checkFileType(filename):
try:
with open(filename, 'rb') as f:
data = f.read()
encoding_type = chardet.detect(data)
return encoding_type['encoding']
except Exception as e:
return 'utf-8'
def changeFileType(filename_in,filename_out='C:\\Users\\19532\\Desktop\\testout.md'):
# 输入文件的编码类型
encode_in = checkFileType(filename_in)
# 输出文件的编码类型
encode_out = 'utf-8'
with codecs.open(filename=filename_in, mode='rb', encoding=encode_in, errors='ignore') as fi:
data = fi.read()
with open(filename_out, mode='w', encoding=encode_out) as fo:
fo.write(data)
fo.close()
return filename_out
# 获取文件的内容
def get_contends(path):
with open(path,'r',encoding='utf-8', errors='ignore') as file_object:
contends = file_object.read()
return contends
def findPos(contends):
pattern = re.compile(r'(-+--|#+ |\$[^\$]+\$|\$\$[^\$]+\$\$|\[|\]|\([^\)]+\)|_+|\*+ |\++ |>+ |`[^`]+`|```[^`]+```|\|+|\n+|---[^-]+---|<[^>]*>)',re.DOTALL)
pos=[]
def double(matched):
pos.append(matched.span())
re.sub(pattern, double,contends)
return pos
def trans2english(contends,pos):
l=0
r=0
i=0
eng=''
while r<len(contends) and i<len(pos):
a=pos[i][0]
b=pos[i][1]
if l<a:
r=a
if contends[l:r]!=' ':
eng+=translet2english(contends[l:r])
else:
eng+=contends[l:r]
l=r
else:
l=b
r=b
eng+=contends[a:b]
i=i+1
if r<len(contends):
if contends[r:len(contends)]!=' ':
eng+=translet2english(contends[r:len(contends)])
else:
eng+=contends[r:len(contends)]
return eng
def readAndTranslate(fileIn='C:\\Users\\19532\\Desktop\\Myblog\\typora\\如何优雅的将中文markdown文件转换为英文markdown文件.md',filename_out='C:\\Users\\19532\\Desktop\\Myblog\\typora\\如何优雅的将中文markdown文件转换为英文markdown文件eng.md'):
filename=changeFileType(fileIn)
contends=get_contends(filename)
pos=findPos(contends)
ans=trans2english(contends,pos)
with open(filename_out, mode='w', encoding= 'utf-8') as fo:
fo.write(ans)
fo.close()
if __name__ == '__main__':
fileIn='C:\\Users\\19532\\Desktop\\Myblog\\typora\\如何优雅的将中文markdown文件转换为英文markdown文件.md'
filename_out=fileIn[:-3]+'eng.md'
readAndTranslate(fileIn,filename_out)

